@DerReisende77 sagte in MediathekView v. 14.3.1 (aarch64) - kein Sortieren in Abo-Liste möglich:
Ist in der aktuellen Nightly definitiv gefixt
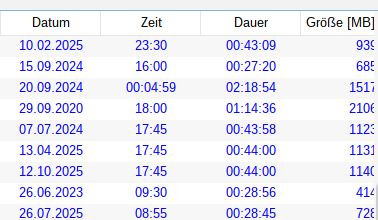
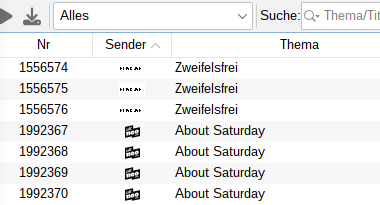
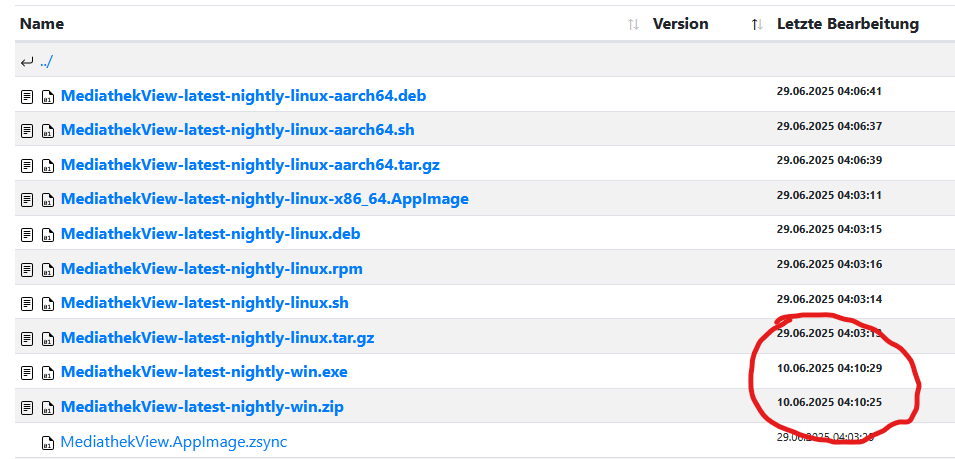
JUHU JUHU 😄 Soeben die 14.6.0-Nightly mit Datum 16.04. heruntergeladen, installiert, gestartet, getestet, und JA, jetzt kann ich sortieren … sehr geil, DANKE!