Tagesschau 24, Alpha und TS vor 20 Jahren
-
Vielen Dank für die fixe Antwort auf diesen “aufgewärmten” Thread! :)
Für ein vollständiges Archiv ist der manuelle Aufwand immens, da fehlt einfach die Zeit - MV wäre die Lösung.
Wenn es einen “Ich habe denselben Wunsch”-Button gäbe, würden sicher etliche Interessenten zusammenkommen.
Stimmt, das zweite Ticket ist das richtige, werde dort eine Notiz hinterlassen!
VG, Steffen -
Du könntest JDownloader nutzen, das Programm mit geeigneten Links “beschicken” und dann die gewünschten Sendungen downloaden lassen:
-
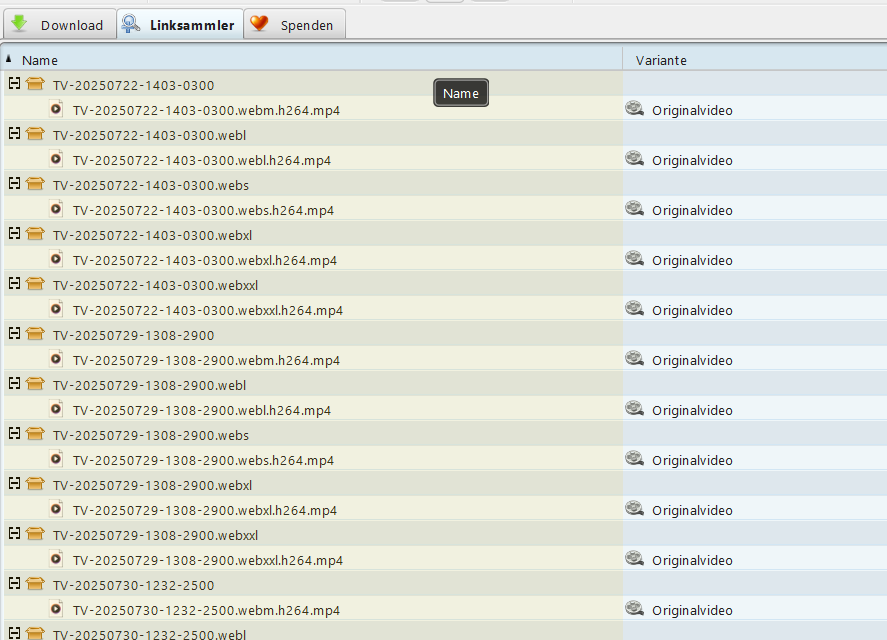
@steffen-c sorry, hast Du meinen Post überhaupt gelesen? Der Screenshot belegt, dass es mit JDownloader funktionieren würde - wenn man denn will. Aber ok, du kannst dir natürlich deinen eigenen crawler bauen. EOD für mich.
-
Hallo,
ich schaue immermal wieder 'rein, ob die “tagesschau vor 20 Jahren” in MV in der Suche auftaucht.
Das Problem scheint ja mit
https://github.com/mediathekview/MServer/issues/845
gefixt zu sein, allerdings bekomme ich noch immer keine Ergebnisse…
Kann mir bitte jemand den Trick verraten, wie ich die “tagesschau vor 20 Jahren” in MV finden und downloaden kann?
Vielen Dank!! Steffen@steffen-c
Gar nicht.
Aber du kannst dir hier alle anschauen.
https://www.tagesschau.de/inland/tsvorzwanzigjahren-ts-142.html -
@steffen-c sorry, hast Du meinen Post überhaupt gelesen? Der Screenshot belegt, dass es mit JDownloader funktionieren würde - wenn man denn will. Aber ok, du kannst dir natürlich deinen eigenen crawler bauen. EOD für mich.
Ja sicher habe ich’s gesehen, gelesen getestet:
- Man gebe in den JD die Adresse der Übersichtsseite ein und hoffe, dass der JD die Seite und Unterseiten/Detailseiten crawlt und Detailseiten und Videos findet:
https://www.tagesschau.de/inland/tsvorzwanzigjahren-ts-142.html
Ergebnis JD: “Content offline!tsvorzwanzigjahren-ts-142.html”
=> funktioniert nicht - Man gebe in den JD die Adresse einer Video-Detailseite ein und hoffe, dass der JD die Seite crawlt und das Video findet:
https://www.tagesschau.de/multimedia/sendung/tagesschau_vor_20_jahren/video-1498332.html
Ergebnis JD: “Content offline!video-1498332.html”
=> funktioniert nicht - Die Links in Deinem Bild legen nahe, dass man die Filenamen u.U. selbst generieren kann.
Meine Tests:
https://media.tagesschau.de/video/2009/1123/TV-20091122-1113-4901.webl.h264.mp4 1. Dezember 1989
https://media.tagesschau.de/video/2009/1123/TV-20091123-1113-4901.webl.h264.mp4 2. Dezember 1989
https://media.tagesschau.de/video/2009/1123/TV-20091123-1133-3501.webl.h264.mp4 3. Dezember 1989
https://media.tagesschau.de/video/2009/1123/TV-20091123-1200-5801.webl.h264.mp4 4. Dezember 1989
https://media.tagesschau.de/video/2009/1124/TV-20091124-1043-4701.webl.h264.mp4 5. Dezember 1989
=> Keine bestimmte Formatierung der Dateinamen für ein bestimmtes Datum erkennbar - Man rufe die Video-Detailseite auf, starte das Video, klicke den erscheinenden Download-LInk an,
suche sich eine Auflösung aus und starte den eigentlichen Video-Download,
breche diesen ab und kopiere den Link des eigentlichen Video-Downloads in JD:
https://media.tagesschau.de/video/2025/0822/TV-20250822-1419-1200.webxxl.h264.mp4
=> Das funktioniert, macht aber keinen Sinn, da ich ja jeden Seite manuell aufrufen und den Link so extrahieren muss.
Meine Schlussfolgerung: Wenn JD nicht selbstständig die Startseite bis zu den Video-Download-Links crawlen kann,
muss man selber einen Crawler schreiben, der die Video-Download-Links extraniert.
Mit diesen Links kann ich dann den JD für die Downloads füttern.
Bitte korrigiere mich, falls ich etwas übersehen habe!
- Man gebe in den JD die Adresse der Übersichtsseite ein und hoffe, dass der JD die Seite und Unterseiten/Detailseiten crawlt und Detailseiten und Videos findet:
-
Du könntest JDownloader nutzen, das Programm mit geeigneten Links “beschicken” und dann die gewünschten Sendungen downloaden lassen:
@DaDirnbocher sagte in Tagesschau 24, Alpha und TS vor 20 Jahren:
Du könntest JDownloader nutzen, das Programm mit geeigneten Links “beschicken” und dann die gewünschten Sendungen downloaden lassen:
Dann erkläre doch mal bitte, wie man zu geeigneten Links kommt. Hier funktioniert der Download mit JDownloader nämlich ebenso wenig. Die Sammellinks liefern keine Treffer und die Links von den einzelnen Sendungen eine Datei mit Namen nach dem Schema Content offline!video-1498332.html die offline ist.
-
Vielen Dank für die fixe Antwort auf diesen “aufgewärmten” Thread! :)
Für ein vollständiges Archiv ist der manuelle Aufwand immens, da fehlt einfach die Zeit - MV wäre die Lösung.
Wenn es einen “Ich habe denselben Wunsch”-Button gäbe, würden sicher etliche Interessenten zusammenkommen.
Stimmt, das zweite Ticket ist das richtige, werde dort eine Notiz hinterlassen!
VG, Steffen@steffen-c sagte: Wenn es einen “Ich habe denselben Wunsch”-Button gäbe, würden sicher etliche Interessenten zusammenkommen.
Das bezweifle ich. Das ganze Archiv ist doch “bloss” für Historiker allgemein oder für Interessierte die Mediengeschichte im Speziellen interessant. Und wenn diese Leute (Universität etc. ) einen andersartigen Zugriff (API) als über die Website auf das ganze Archiv benötigen, dürften sie diesen wohl auf entsprechende Nachfrage auch kriegen (sofern technisch schon möglich). Aber auch dann laden die wohl kaum einfach alles runter, wie du das willst.
Gewöhnliche User sind eh nur an einem Thema oder einer Zeitspanne interessiert und laden die ausgewählten Einträge herunter.
@vitusson sagte in Tagesschau 24, Alpha und TS vor 20 Jahren:
Aber du kannst dir hier alle anschauen.
https://www.tagesschau.de/inland/tsvorzwanzigjahren-ts-142.htmlAndere haben sogar erwähnt, dass man genau dort auch jede Sendung nicht nur anschauen, sondern auch herunterladen kann (genau, was @steffen-c will)…
Wieder nix gelesen, aber trotzdem kommentiert…
@DaDirnbocher sagte: Der Screenshot belegt, dass es mit JDownloader funktionieren würde - wenn man denn will.
Ich lerne gerne dazu. Hätte mich jetzt auch noch interessiert, wie das damit geht.
-
@steffen-c sagte: Wenn es einen “Ich habe denselben Wunsch”-Button gäbe, würden sicher etliche Interessenten zusammenkommen.
Das bezweifle ich. Das ganze Archiv ist doch “bloss” für Historiker allgemein oder für Interessierte die Mediengeschichte im Speziellen interessant. Und wenn diese Leute (Universität etc. ) einen andersartigen Zugriff (API) als über die Website auf das ganze Archiv benötigen, dürften sie diesen wohl auf entsprechende Nachfrage auch kriegen (sofern technisch schon möglich). Aber auch dann laden die wohl kaum einfach alles runter, wie du das willst.
Gewöhnliche User sind eh nur an einem Thema oder einer Zeitspanne interessiert und laden die ausgewählten Einträge herunter.
@vitusson sagte in Tagesschau 24, Alpha und TS vor 20 Jahren:
Aber du kannst dir hier alle anschauen.
https://www.tagesschau.de/inland/tsvorzwanzigjahren-ts-142.htmlAndere haben sogar erwähnt, dass man genau dort auch jede Sendung nicht nur anschauen, sondern auch herunterladen kann (genau, was @steffen-c will)…
Wieder nix gelesen, aber trotzdem kommentiert…
@DaDirnbocher sagte: Der Screenshot belegt, dass es mit JDownloader funktionieren würde - wenn man denn will.
Ich lerne gerne dazu. Hätte mich jetzt auch noch interessiert, wie das damit geht.
@styroll
Die “tagesschau vor 20 Jahren” ist IMO geschichtsträchtig und sollte unbedingt archiviert werden.
Gerade die Vergleiche damals-heute finde ich extrem interessant,
nur wer die Vergangenheit kennt <blabla> usw…, da muss man keine Intelligenzbestie sein… ;)
Wenn irgendwan mal die Kohle im, ÖR knapp wird, kann das Angebot ganz schnell wieder weg sein.
Für ein vollständiges Archiv ist der manuelle Aufwand, sich durch jedes Video zu klicken und einzeln zu downloaden, immens, da fehlt einfach die Zeit.
