Vorschlag zum 1. Filmliste-Objekt in der Filmliste
-
Muss ich verstehen, weshalb ein Programm schneller wird, wenn es mehr Funktionen enthält?
-
Die Änderung werden wir nicht umsetzen, weil keiner der von uns gewarteten Clients die Änderung benötigt und eine Änderung am Dateiformat unnötiges Risiko bei den Clients erzeugt.
Des Weiteren wollen wir das Dateiformat lieber früher als später loswerden und auf ein moderneres und leichter erweiterbares Format setzen.
-
IMoin,
es ist immer wieder interessant wie man missverstanden werden kann. :(Es geht nicht darum das es nicht möglich ist die Anzahl der Filme irgendwie zu erhalten. Sondern dasrum das Prg mit ganz wenig Aufwand weniger aufwändig und schneller zu machen.
Mit freundlichen Grüßen
Dexli@Dexli sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
IMoin,
es ist immer wieder interessant wie man missverstanden werden kann. :(Es geht nicht darum das es nicht möglich ist die Anzahl der Filme irgendwie zu erhalten. Sondern dasrum das Prg mit ganz wenig Aufwand weniger aufwändig und schneller zu machen.
Mit freundlichen Grüßen
DexliSag einfach klar was du vor hast und was du brauchst und warum und du bekommst auch bessere Antworten.
Aber einfach immer nur Wünsche mit ein paar snippets einwerfen und sich dann beschweren geht halt auch. -
Muss ich verstehen, weshalb ein Programm schneller wird, wenn es mehr Funktionen enthält?
Moin,
Muss ich verstehen, weshalb ein Programm schneller wird, wenn es mehr Funktionen enthält?
Man braucht keine zusätzliche Funktion, sonder lediglich eine schon vorhandene Funktion um das Herausschreiben eines zusätzlichen (aber vorhandenen ) Wertes erweitern und wenn man die Information bei Einlesen nicht nutzen will diese einfach zu ignorieren.
Wie schon oben beschrieben, ermöglicht dieser Wert es beim Einlesen einen Teil des benötigten Speichers in einem Rutsch zu allozieren und nicht bei jedem Einfügen zu testen ob man weiteren Speicher braucht und ggf. mehrfach Speicher in anderen Speicherbereichen zu allozieren und den schon vorhandenen Speicher zu kopieren, bzw. die Speicherfragmente zu verwalten. Bei kleinen Listen würde das sicher nicht so ins Gewicht fallen, bei der großen Anzahl der Filme > 800K macht das schon einen Unterschied. (Obwohl MV schon deutlich schneller geworden ist)
Die Änderung werden wir nicht umsetzen, weil keiner der von uns gewarteten Clients die Änderung benötigt und eine Änderung am Dateiformat unnötiges Risiko bei den Clients erzeugt.
Das ist ein gutes Argument! Bei Projekten die mit der Zeit generisch gewachsen sind, hat man immer mit Altlasten zu kämpfen, die gewisse Instabilitäten/Inkonsistenzen erzeugen.
Des Weiteren wollen wir das Dateiformat lieber früher als später loswerden und auf ein moderneres und leichter erweiterbares Format setzen.
Auch das ist ein guter Grund! Gibt es schon entsprechende Diskussionen was euch da vorschwebt?
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.@vitusson
MIr ist die aktuelle Gui zu groß (auch die Speichernutzung) und zu unflexibel was die Suche angeht. Das Bashscript ist was die Suche angeht schon gut, aber eben ein commandline tool. Daher habe ich für mich überlegt eine C/C++ Lib zu bauen die unabhängig von einer Gui das Handling der Filmliste und der Suche realisiert. Eine Basis Gui würde ich mit QT realisieren. Das wäre aber erstmal ein reines Hobbyprojekt für mich , welches ich erst veröffentlich würde wenn es einen halbwegs stabilen Zustand erreicht hätte.Im übrigen habe ich mich nicht beschwert, denn wenn man fragte “wie spät ist es” und die Antwort “Drei Euro Fünfzig” ist, dann liegt einfach ein Missverständniss vor ;-)
Um das Ganze aber abzuschließen, da der Vorschlag anscheinend keine Chance hat umgesetzt zu werden, werde ich das anders umsetzen müssen.
Was das angestrebte neue Format angeht, fände ich es schön wenn es Informationen zu der angedachten Richtung gäbe.Viele Grüße und ein schönes Wochenende
Dexli
Edit: typo -
Moin,
Muss ich verstehen, weshalb ein Programm schneller wird, wenn es mehr Funktionen enthält?
Man braucht keine zusätzliche Funktion, sonder lediglich eine schon vorhandene Funktion um das Herausschreiben eines zusätzlichen (aber vorhandenen ) Wertes erweitern und wenn man die Information bei Einlesen nicht nutzen will diese einfach zu ignorieren.
Wie schon oben beschrieben, ermöglicht dieser Wert es beim Einlesen einen Teil des benötigten Speichers in einem Rutsch zu allozieren und nicht bei jedem Einfügen zu testen ob man weiteren Speicher braucht und ggf. mehrfach Speicher in anderen Speicherbereichen zu allozieren und den schon vorhandenen Speicher zu kopieren, bzw. die Speicherfragmente zu verwalten. Bei kleinen Listen würde das sicher nicht so ins Gewicht fallen, bei der großen Anzahl der Filme > 800K macht das schon einen Unterschied. (Obwohl MV schon deutlich schneller geworden ist)
Die Änderung werden wir nicht umsetzen, weil keiner der von uns gewarteten Clients die Änderung benötigt und eine Änderung am Dateiformat unnötiges Risiko bei den Clients erzeugt.
Das ist ein gutes Argument! Bei Projekten die mit der Zeit generisch gewachsen sind, hat man immer mit Altlasten zu kämpfen, die gewisse Instabilitäten/Inkonsistenzen erzeugen.
Des Weiteren wollen wir das Dateiformat lieber früher als später loswerden und auf ein moderneres und leichter erweiterbares Format setzen.
Auch das ist ein guter Grund! Gibt es schon entsprechende Diskussionen was euch da vorschwebt?
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.@vitusson
MIr ist die aktuelle Gui zu groß (auch die Speichernutzung) und zu unflexibel was die Suche angeht. Das Bashscript ist was die Suche angeht schon gut, aber eben ein commandline tool. Daher habe ich für mich überlegt eine C/C++ Lib zu bauen die unabhängig von einer Gui das Handling der Filmliste und der Suche realisiert. Eine Basis Gui würde ich mit QT realisieren. Das wäre aber erstmal ein reines Hobbyprojekt für mich , welches ich erst veröffentlich würde wenn es einen halbwegs stabilen Zustand erreicht hätte.Im übrigen habe ich mich nicht beschwert, denn wenn man fragte “wie spät ist es” und die Antwort “Drei Euro Fünfzig” ist, dann liegt einfach ein Missverständniss vor ;-)
Um das Ganze aber abzuschließen, da der Vorschlag anscheinend keine Chance hat umgesetzt zu werden, werde ich das anders umsetzen müssen.
Was das angestrebte neue Format angeht, fände ich es schön wenn es Informationen zu der angedachten Richtung gäbe.Viele Grüße und ein schönes Wochenende
Dexli
Edit: typo@Dexli sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
MIr ist die aktuelle Gui zu groß (auch die Speichernutzung) und zu unflexibel was die Suche angeht
Du kennst die “Moderne Suche” in MV? Du hast diese aktiviert? Und die ist Dir zu unflexibel?
-
Moin,
Muss ich verstehen, weshalb ein Programm schneller wird, wenn es mehr Funktionen enthält?
Man braucht keine zusätzliche Funktion, sonder lediglich eine schon vorhandene Funktion um das Herausschreiben eines zusätzlichen (aber vorhandenen ) Wertes erweitern und wenn man die Information bei Einlesen nicht nutzen will diese einfach zu ignorieren.
Wie schon oben beschrieben, ermöglicht dieser Wert es beim Einlesen einen Teil des benötigten Speichers in einem Rutsch zu allozieren und nicht bei jedem Einfügen zu testen ob man weiteren Speicher braucht und ggf. mehrfach Speicher in anderen Speicherbereichen zu allozieren und den schon vorhandenen Speicher zu kopieren, bzw. die Speicherfragmente zu verwalten. Bei kleinen Listen würde das sicher nicht so ins Gewicht fallen, bei der großen Anzahl der Filme > 800K macht das schon einen Unterschied. (Obwohl MV schon deutlich schneller geworden ist)
Die Änderung werden wir nicht umsetzen, weil keiner der von uns gewarteten Clients die Änderung benötigt und eine Änderung am Dateiformat unnötiges Risiko bei den Clients erzeugt.
Das ist ein gutes Argument! Bei Projekten die mit der Zeit generisch gewachsen sind, hat man immer mit Altlasten zu kämpfen, die gewisse Instabilitäten/Inkonsistenzen erzeugen.
Des Weiteren wollen wir das Dateiformat lieber früher als später loswerden und auf ein moderneres und leichter erweiterbares Format setzen.
Auch das ist ein guter Grund! Gibt es schon entsprechende Diskussionen was euch da vorschwebt?
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.@vitusson
MIr ist die aktuelle Gui zu groß (auch die Speichernutzung) und zu unflexibel was die Suche angeht. Das Bashscript ist was die Suche angeht schon gut, aber eben ein commandline tool. Daher habe ich für mich überlegt eine C/C++ Lib zu bauen die unabhängig von einer Gui das Handling der Filmliste und der Suche realisiert. Eine Basis Gui würde ich mit QT realisieren. Das wäre aber erstmal ein reines Hobbyprojekt für mich , welches ich erst veröffentlich würde wenn es einen halbwegs stabilen Zustand erreicht hätte.Im übrigen habe ich mich nicht beschwert, denn wenn man fragte “wie spät ist es” und die Antwort “Drei Euro Fünfzig” ist, dann liegt einfach ein Missverständniss vor ;-)
Um das Ganze aber abzuschließen, da der Vorschlag anscheinend keine Chance hat umgesetzt zu werden, werde ich das anders umsetzen müssen.
Was das angestrebte neue Format angeht, fände ich es schön wenn es Informationen zu der angedachten Richtung gäbe.Viele Grüße und ein schönes Wochenende
Dexli
Edit: typo@Dexli sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
Wie schon oben beschrieben, ermöglicht dieser Wert es beim Einlesen einen Teil des benötigten Speichers in einem Rutsch zu allozieren und nicht bei jedem Einfügen zu testen ob man weiteren Speicher braucht und ggf. mehrfach Speicher in anderen Speicherbereichen zu allozieren und den schon vorhandenen Speicher zu kopieren, bzw. die Speicherfragmente zu verwalten. Bei kleinen Listen würde das sicher nicht so ins Gewicht fallen, bei der großen Anzahl der Filme > 800K macht das schon einen Unterschied. (Obwohl MV schon deutlich schneller geworden ist)
Ich glaube Du betreibst hier micro optimization die nicht notwendig ist. Eine eben getestete Filmliste mit 837880 Einträgen belegt in Java laut Profiler 54 MB RAM.
Mit einem privaten C++ Programm verarbeite ich die Liste auf meinem Laptop ohne irgendwelche Optimierungen entspannt unter 2 Sekunden.
Letztendlich hängt das ganze aber auch davon ab wieviel Verarbeitung du durchführst.
Ich habe einen quick&dirty Benchmark mal für dein Problem gemacht welcher je nach Verarbeitungsaufwand entweder gleich schnell ist mit preallocation bzw. 1,4x schneller. Am Ende glaube ich persönlich ist es aber total egal. Zumal es auch stark abhängig ist ob man MSVC compiler oder gcc/clang verwendet.Daneben ist bei MV nicht das parsen das “Problem”, sondern das filtern und vor allem das darstellen des Modells durch die Swing Tabelle.
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.Dafür hat Gott Verrückte erschaffen die Kompressionsalgorithmen basteln. Die schaffen es auch jetzt schon, die 598MB große Filmliste auf 92 MB einzudampfen. Das wird beim Download ja schon so praktiziert. Von daher ist es aus meiner Sicht unnötig da etwas kompliziertes selbst zu basteln was wenig zusätzlichen Benefit liefert.
-
@Dexli sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
Wie schon oben beschrieben, ermöglicht dieser Wert es beim Einlesen einen Teil des benötigten Speichers in einem Rutsch zu allozieren und nicht bei jedem Einfügen zu testen ob man weiteren Speicher braucht und ggf. mehrfach Speicher in anderen Speicherbereichen zu allozieren und den schon vorhandenen Speicher zu kopieren, bzw. die Speicherfragmente zu verwalten. Bei kleinen Listen würde das sicher nicht so ins Gewicht fallen, bei der großen Anzahl der Filme > 800K macht das schon einen Unterschied. (Obwohl MV schon deutlich schneller geworden ist)
Ich glaube Du betreibst hier micro optimization die nicht notwendig ist. Eine eben getestete Filmliste mit 837880 Einträgen belegt in Java laut Profiler 54 MB RAM.
Mit einem privaten C++ Programm verarbeite ich die Liste auf meinem Laptop ohne irgendwelche Optimierungen entspannt unter 2 Sekunden.
Letztendlich hängt das ganze aber auch davon ab wieviel Verarbeitung du durchführst.
Ich habe einen quick&dirty Benchmark mal für dein Problem gemacht welcher je nach Verarbeitungsaufwand entweder gleich schnell ist mit preallocation bzw. 1,4x schneller. Am Ende glaube ich persönlich ist es aber total egal. Zumal es auch stark abhängig ist ob man MSVC compiler oder gcc/clang verwendet.Daneben ist bei MV nicht das parsen das “Problem”, sondern das filtern und vor allem das darstellen des Modells durch die Swing Tabelle.
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.Dafür hat Gott Verrückte erschaffen die Kompressionsalgorithmen basteln. Die schaffen es auch jetzt schon, die 598MB große Filmliste auf 92 MB einzudampfen. Das wird beim Download ja schon so praktiziert. Von daher ist es aus meiner Sicht unnötig da etwas kompliziertes selbst zu basteln was wenig zusätzlichen Benefit liefert.
Moin,
@DerReisende77 sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
Ich glaube Du betreibst hier micro optimization die nicht notwendig ist.
Das kann ich erst sagen wenn ich das mal ausprobiert habe ;-)
Eine eben getestete Filmliste mit 837880 Einträgen belegt in Java laut Profiler 54 MB RAM.
Wenn ich das mal grob überschlage, glaube ich nicht, dass Du da alle 837880 Einträge gleichzeitig im Speicher hast.
Mit einem privaten C++ Programm verarbeite ich die Liste auf meinem Laptop ohne irgendwelche Optimierungen entspannt unter 2 Sekunden.
Das kommt sicher auch auf die Maschine an.
Letztendlich hängt das ganze aber auch davon ab wieviel Verarbeitung du durchführst.
Welche Verarbeitung führst Du denn bei deinem privaten Prg durch ?
Ich habe einen quick&dirty Benchmark mal für dein Problem gemacht welcher je nach Verarbeitungsaufwand entweder gleich schnell ist mit preallocation bzw. 1,4x schneller.
Ich habe mir das mal angesehen und ich komme auf den Faktor 1,5 was letzten Endes 50% wäre. Dabei ist der Faktor extrem davon abhängig wie der Zufallsstring erzeugt wird, was nicht daür spricht das der Benchmark die (Pre)Allocation abbildet.
Leider kenne ich das Tool nicht und habe auch keine brauchbare Dokumentation gefunden. Daher bin daran gescheitert einmal einen globalen Film-Vektor zu erzeugen, der dann von beiden Routinen als Quelle genutzt wird.Am Ende glaube ich persönlich ist es aber total egal. Zumal es auch stark abhängig ist ob man MSVC compiler oder gcc/clang verwendet.
Auch wenn ich Dir rechtgebe das der verwendete Kompiler einen nicht zu unterschätzenden Einfluss hat, ist es wie überall, Kleinvieh macht aus Mist. Hier mal 30% dort weitere 10 … In der Summe macht es dann doch einen nennenswerten Unterschied. Hinzukommt, das diese Unterschiede sich um so stärker auswirken je leistungsschwacher der Rechner ist. (z.B. ein RasPi)
Daneben ist bei MV nicht das parsen das “Problem”, sondern das filtern und vor allem das darstellen des Modells durch die Swing Tabelle.
Da ich mich mit Java nur sehr rudimentär (eigentlich garnicht, vor über 20 Jahren mal was damit gemacht) auskenne glaube ich das sofort.
Was mir in diesem Zusammenhang auffällt ist, z.B die große Redundanz bezüglich der URLs. So taucht der String nrodlzdf-a.akamaihd.net/none/ alleine schon min über 135000 mal auf, andere Strings wie
‘nrodlzdf-a.akamaihd.net/none/’ oder ‘nrodlzdf-a.akamaihd.net/none’ jeweils mehrere zig-tausend mal.
Ein neues Format könnte solche Redundanzen intelligent ausnutzen um eine Menge Platz zu sparen.Dafür hat Gott Verrückte erschaffen die Kompressionsalgorithmen basteln.
grins ja die sind schon Klasse!
Allerdings ist dabei das Problem, dass man (nach meinem Kenntnisstand) nur sequenziell damit arbeiten kann und nicht auf direkt auf Element N-M zugreifen kann.Die schaffen es auch jetzt schon, die 598MB große Filmliste auf 92 MB einzudampfen. Das wird beim Download ja schon so praktiziert. Von daher ist es aus meiner Sicht unnötig da etwas kompliziertes selbst zu basteln was wenig zusätzlichen Benefit liefert.
So kompliziert wäre das m.E. nach nicht. Sowas ähnliches macht ihr ja schon, wenn man das konsequent weiter denkt hat man eine Liste mit den Strings mit denen die URLs beginnen. Der Index auf diese Liste wäre dann einfach ein uint16 für jedes URL-Feld.
Aber wie schon mal gefragt, in welche Richtung soll sich das neue Format entwickeln ?
Viele Grüße
Dexli -
@Dexli sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
Moin,
@DerReisende77 sagte in Vorschlag zum 1. Filmliste-Objekt in der Filmliste:
Eine eben getestete Filmliste mit 837880 Einträgen belegt in Java laut Profiler 54 MB RAM.
Wenn ich das mal grob überschlage, glaube ich nicht, dass Du da alle 837880 Einträge gleichzeitig im Speicher hast.
Wenn ich das nicht überschlage sondern mit einem Profiler messe glaube ich dem das schon ziemlich genau. Davon abgesehen kann man das sehr leicht nachrechnen:
54MB = 56623104 bytes; 56623104 / 837880 =67,579 bytes pro DatenFilm Objekt.
Mit einem weiteren freundlichen Java Tool kann ich folgendes rausfinden:
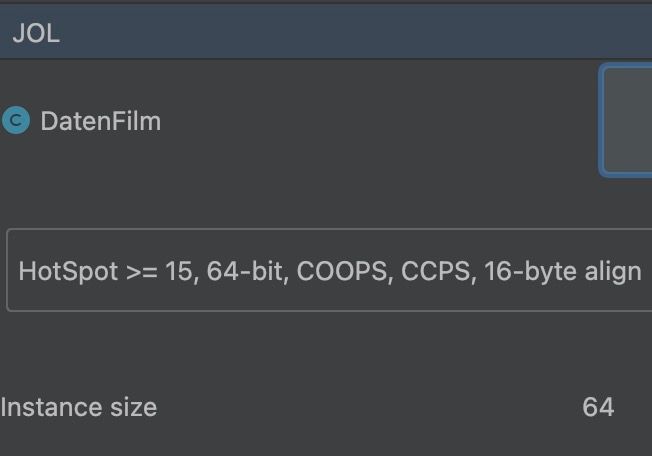
Huch, die JavaVM sagt meine Instanz braucht nur 64 bytes. Also alles kein Glaube sondern Wissen ;)
Mit einem privaten C++ Programm verarbeite ich die Liste auf meinem Laptop ohne irgendwelche Optimierungen entspannt unter 2 Sekunden.
Das kommt sicher auch auf die Maschine an.
Apple M1Ich habe einen quick&dirty Benchmark mal für dein Problem gemacht welcher je nach Verarbeitungsaufwand entweder gleich schnell ist mit preallocation bzw. 1,4x schneller.
Ich habe mir das mal angesehen und ich komme auf den Faktor 1,5 was letzten Endes 50% wäre.
Ob Faktor 1,4 oder 1,5 ist egal, das Tool bildet die Mittelwerte aus der Leistungsfähigkeit der genutzten AWS Instanzen. Ist in der Hilfe dokumentiert.
Dabei ist der Faktor extrem davon abhängig wie der Zufallsstring erzeugt wird, was nicht daür spricht das der Benchmark die (Pre)Allocation abbildet.
Das ist doch genau der Punkt bei dem Benchmark! Wenn Du wenig Operationen beim Parsen zusätzlich durchführen musst kriegst du deine 40-50% mehr speed. Musst Du jedoch ein paar string ops durchführen (was sehr wahrscheinlich ist) geht der performance so schnell runter dass kein benefit mehr da ist. Und genau das zeigt der benchmark.
Aber wie schon mal gefragt, in welche Richtung soll sich das neue Format entwickeln ?
JSON wohl, ob als Dokument analog zur bisherigen Liste oder als document-based database steht noch nicht fest.
-
@Georg-J Falscher Ansatz. Du musst die unkomprimierte Liste als Vergleich heranziehen. Am Ende des Tages wird die Textliste gelesen und dann in Programmcode umgesetzt - der ist kleiner und natürlich optimierter.
-
Sorry für das späte Reply, ging leider nicht früher.
68 Byte pro Eintrag, das deckt ja noch nicht einmal eine URL ab. Ich habe mal einen Eintrag ausgezählt und bin locker über 500 Byte gelandet.
Selbst wenn das nicht für alle Einträge gilt, sind die 68 Byte pro Eintrag garantiert nicht zu erreichen, es sei denn, man arbeitet mit einem Dictionary wie vorgeschlagen und im Eintrag mit Indizes darauf. und selbst dann wird es ausgesprochen knapp, denn bei 20 Feldern sind das 3,4 Byte pro Feld. Ich vermute mal das hier im Hintergrund die Funktion MMap genutzt wird die eine Datei transparent in den Speicher mappt.
Außerdem sind es nicht 54 MB sondern über 500 MB wie Du selber am 09.3.2025 geschrieben hastDafür hat Gott Verrückte erschaffen die Kompressionsalgorithmen basteln. Die schaffen es auch jetzt schon, die 598MB große Filmliste auf 92 MB einzudampfen.
Das ist doch genau der Punkt bei dem Benchmark! Wenn Du wenig Operationen beim Parsen zusätzlich durchführen musst kriegst du deine 40-50% mehr speed. Musst Du jedoch ein paar string ops durchführen (was sehr wahrscheinlich ist) geht der performance so schnell runter dass kein benefit mehr da ist. Und genau das zeigt der benchmark.
Also selbst wenn es nur 30% sind ist das m.E. eine signifikante Steigerung. Stringops im Speicher sind sehr schnell, Erzeugung von Zufallszahlen sind deutlich langsamer.
Viele Grüße
Dexli