SMB
-
Hallo,
also in meinem normalen Anwendungsfall ist in 13.2 gegenüber 13.1 die Schreibgeschwindigkeit auf ca. 5%-10% gefallen und hat damit leider wieder die Qualität von MV 12.
Ich hab MV aufm Laptop (normalerweise unter Windows 10 18.04 x64 Prof) offen und speichere direkt auf eine SMB Freigabe meines NAS. (NAS ist per GBit Kabel an der FB. FB mit 200 MBit downstream im Internet. Laptop mit effektiv 200 MBit WLAN an der FB. PC mit effektiv 1000 MBit an NAS).
Download mit MV 13.2 auf lokale NTFS SSD ~120 MBit.
Download mit MV 13.2 auf Samba Freigabe des NAS mit ~2-4 MBit
Download mit MV 13.1 auf Samba Freigabe des NAS mit ~60-80 MBit.
Download mitm Browser auf die Samba Freigabe des NAS rennt mit ~80 MBit.
Kopieren von Laptop auf NAS große Dateien mit ~120 - 200 MBit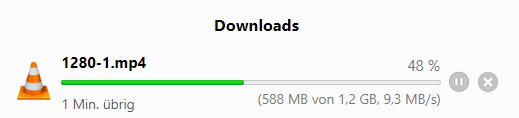

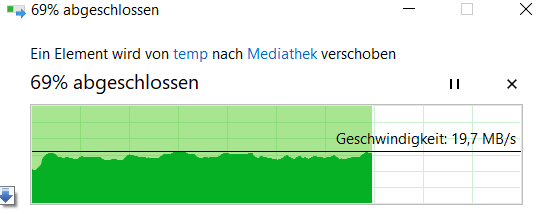
Hat jemand ähnliche Erfahrungen mit Netzlaufwerken?
Programmstart: 29.08.2018 19:23:37
maxMemory: 1234 MB
Version: MediathekView 13.2.0
Java:
Vendor: Oracle Corporation
VMname: Java HotSpot™ 64-Bit Server VM
Version: 1.8.0_181
Runtimeversion: 1.8.0_181-b13 -
Ohne ein Netzlaufwerk zur Hand zu haben könnte es daran liegen das 13.2 die Daten byte-weise schreibt. Windows hat ein Talent da sauer zu reagieren und Geschwindigkeit zu verlieren während UNIXoide Systeme das ohne Probleme verdauen. Leider ist dies in 13.2 notwendig damit die Drosselung vernünftig funktioniert. In 13.1 wurden die Schreibzugriffe zusammengefasst und in 64K Bündel an Windows weiter gereicht. Aber dort hat dann auch die Drosselung nur unzuverlässig funktioniert. Ein workaround ist hierfür aber nicht ohne weiteres drin.
-
Ok. Klingt ebenso entsetzlich wie intuitiv plausibel. Vorschlag meinerseits: Du sagst mir die Klasse(n)/Paket(e) im src, wo Du die Bremse vermutest und ich schau mir die Stelle mal an, ob ich Ideen dazu habe. So ein ganz kleines bissl Java kann ich auch. (Oder ich bau ein CArchive aus der MFC um das File herum :-p)
Außerdem teste ich mal, ob ich am (kabelgebundenen) PC dasselbe Problem habe (lokale NTFS Platte zig mal schneller SAMBA Netzlaufwerk), unter Windows 10. Evtl seh ich ja in einem Gegentest in einer Ubuntu VM oder Debian VM oder nativ mit Knoppix, ob mein Rechner unter Linux dieses Problem nicht doch auch hat.
Der Laptop hat eigentlich nicht genug Platz für dualboot / Linux VM. Höchstens mitm USB-Stick…Also, es is nur meine persönliche Meinung, aber mir persönlich ist Drosselung der Downloads 100% unwichtig. Bei mir funktioniert z.B. auch nicht die Begrenzung der Anzahl der Downloads nicht (es werden nicht entsprechend viele Downloads zB 5 geöffnet auch nicht wenn ich 5 Downloads aus 5 verschiedenen Mediatheken in der Queue habe (ORF, SRF, ZDF, ARTE, ARD), sondern immer nur 2) –
die Downloadbremse ist für mich persönlich dagegen ECHT bitter, und ich möchte aufm Laptop kein Linux reinschrauben, weil das Display etc. da nicht sauber unterstützt wird.
Drum, ich schau mir einfach mal den Code an. -
Ok. Klingt ebenso entsetzlich wie intuitiv plausibel. Vorschlag meinerseits: Du sagst mir die Klasse(n)/Paket(e) im src, wo Du die Bremse vermutest und ich schau mir die Stelle mal an, ob ich Ideen dazu habe. So ein ganz kleines bissl Java kann ich auch. (Oder ich bau ein CArchive aus der MFC um das File herum :-p)
Außerdem teste ich mal, ob ich am (kabelgebundenen) PC dasselbe Problem habe (lokale NTFS Platte zig mal schneller SAMBA Netzlaufwerk), unter Windows 10. Evtl seh ich ja in einem Gegentest in einer Ubuntu VM oder Debian VM oder nativ mit Knoppix, ob mein Rechner unter Linux dieses Problem nicht doch auch hat.
Der Laptop hat eigentlich nicht genug Platz für dualboot / Linux VM. Höchstens mitm USB-Stick…Also, es is nur meine persönliche Meinung, aber mir persönlich ist Drosselung der Downloads 100% unwichtig. Bei mir funktioniert z.B. auch nicht die Begrenzung der Anzahl der Downloads nicht (es werden nicht entsprechend viele Downloads zB 5 geöffnet auch nicht wenn ich 5 Downloads aus 5 verschiedenen Mediatheken in der Queue habe (ORF, SRF, ZDF, ARTE, ARD), sondern immer nur 2) –
die Downloadbremse ist für mich persönlich dagegen ECHT bitter, und ich möchte aufm Laptop kein Linux reinschrauben, weil das Display etc. da nicht sauber unterstützt wird.
Drum, ich schau mir einfach mal den Code an.@korbinianw sagte: Bei mir funktioniert z.B. auch nicht die Begrenzung der Anzahl der Downloads nicht (es werden nicht entsprechend viele Downloads zB 5 geöffnet auch nicht wenn ich 5 Downloads aus 5 verschiedenen Mediatheken in der Queue habe (ORF, SRF, ZDF, ARTE, ARD), sondern immer nur 2)
Die Limitierung ist eben nicht pro Mediathek, sondern pro Server. Wenn dahinter dann immer ein Akamai-Server steht, wäre deine Beobachtung erklärbar. Auf der anderen Seite macht eine Drosselung bei CDNs wie Akamai keinen Sinn (das war früher anders, als die Sender noch ihre eigenen Video-Server hatten).
-
Ok. Klingt ebenso entsetzlich wie intuitiv plausibel. Vorschlag meinerseits: Du sagst mir die Klasse(n)/Paket(e) im src, wo Du die Bremse vermutest und ich schau mir die Stelle mal an, ob ich Ideen dazu habe. So ein ganz kleines bissl Java kann ich auch. (Oder ich bau ein CArchive aus der MFC um das File herum :-p)
Außerdem teste ich mal, ob ich am (kabelgebundenen) PC dasselbe Problem habe (lokale NTFS Platte zig mal schneller SAMBA Netzlaufwerk), unter Windows 10. Evtl seh ich ja in einem Gegentest in einer Ubuntu VM oder Debian VM oder nativ mit Knoppix, ob mein Rechner unter Linux dieses Problem nicht doch auch hat.
Der Laptop hat eigentlich nicht genug Platz für dualboot / Linux VM. Höchstens mitm USB-Stick…Also, es is nur meine persönliche Meinung, aber mir persönlich ist Drosselung der Downloads 100% unwichtig. Bei mir funktioniert z.B. auch nicht die Begrenzung der Anzahl der Downloads nicht (es werden nicht entsprechend viele Downloads zB 5 geöffnet auch nicht wenn ich 5 Downloads aus 5 verschiedenen Mediatheken in der Queue habe (ORF, SRF, ZDF, ARTE, ARD), sondern immer nur 2) –
die Downloadbremse ist für mich persönlich dagegen ECHT bitter, und ich möchte aufm Laptop kein Linux reinschrauben, weil das Display etc. da nicht sauber unterstützt wird.
Drum, ich schau mir einfach mal den Code an.@korbinianw ich bin heute gut gelaunt und deshalb:
package mediathek.controller.starter;
Klasse: DirectHttpDownload
Funktion: private void downloadContent()Ersetze im try(…) Block den code durch folgenden:
try (FileOutputStream fos = new FileOutputStream(file, (downloaded != 0)); BufferedOutputStream bos = new BufferedOutputStream(fos); ThrottlingInputStream tis = new ThrottlingInputStream(conn.getInputStream(), rateLimiter); MVBandwidthCountingInputStream mvis = new MVBandwidthCountingInputStream(tis, bandwidthCalculationTimer)) { start.mVBandwidthCountingInputStream = mvis; datenDownload.mVFilmSize.addAktSize(downloaded); final byte[] buffer = new byte[1024]; long p, pp = 0, startProzent = -1; int len; long aktBandwidth, aktSize = 0; boolean melden = false; while ((len = start.mVBandwidthCountingInputStream.read(buffer)) != -1 && (!start.stoppen)) { downloaded += len; bos.write(buffer, 0, len); datenDownload.mVFilmSize.addAktSize(len);`Wichtig is fos.write(buffer,0,len) durch bos.write() zu ersetzen.
Bin gespannt auf die Geschwindigkeit im Netzwerk.
-
Wie gesagt: der PC hat mit GBit Kabel eine mindestens 5x so gute Intranetanbindung wie der Laptop mit WLAN 200MBit (effektiv). Und ich hab aufm PC 4x so viel RAM, CPU-Kerne, SSDs und ne bessere Taktfrequenz.
In Sachen MV Downloads ist aber der PC unter Windows mit MV 13.2 etwas mehr als 10x langsamer als der Laptop unter Windows mit MV 13.2 , der etwa 10x - 20x langsamer ist als der Windows Laptop mit MV 13.1.3.
Win 10 (host) MV 13.2

Ubuntu (18.04) (VM) MV 13.2
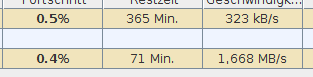
also ist die Linux VM mit 13.2 aufs Netzwerk aufs erste Hingucken so 10x schneller als derselbe Computer als Windows 10 host. Aber da mag ich ein paar Meßwerte mehr haben. heute nimmer.
PC mit MV 13.1.3 meß ich dann am Wochenende; und den Code schau ich mir auch am Wochenende an. Der Whisky ist zu gut heute ;-)
-
Lad dir mal bitte die JAR von folgendem Link und ersetze deine damit. In der ist der Puffer fix eingebaut. Bin gespannt auf Vergleichswerte bei dir:
MV 13.2 -
Lad dir mal bitte die JAR von folgendem Link und ersetze deine damit. In der ist der Puffer fix eingebaut. Bin gespannt auf Vergleichswerte bei dir:
MV 13.2frei nach dem Motto 1000 Bilder sagt mehr als 1 Wort:
(alle Bilder erstellt mit Desktop PC, am Intranet per Kabel (GBit), Internet 200 MBit (downstream))Ich hab mir jeweils 2 Folgen der Serie Elven von Arte.DE geholt. Jeweils 1 Folge lokal gespeichert (bei Knoppix auf USB-Stick), 1 Folge auf die Netzwerkfreigabe.
13.1.3
Knoppix nativ (lokal oben, Netz unten)

Ubuntu VM (Win10 vmware Player)
(fehlt, weil Fauli Schlumpf)Win 10

Original 13.2.0
Knoppix nativ (Netz unten)

Ubuntu VM (Win10 vmware Player)

Win 10

Modifizierte 13.2.0
Knoppix nativ (Netz oben)

Ubuntu VM (Win10 vmware Player)

Win 10

-
Ohne ein Netzlaufwerk zur Hand zu haben könnte es daran liegen das 13.2 die Daten byte-weise schreibt. Windows hat ein Talent da sauer zu reagieren und Geschwindigkeit zu verlieren während UNIXoide Systeme das ohne Probleme verdauen. Leider ist dies in 13.2 notwendig damit die Drosselung vernünftig funktioniert. In 13.1 wurden die Schreibzugriffe zusammengefasst und in 64K Bündel an Windows weiter gereicht. Aber dort hat dann auch die Drosselung nur unzuverlässig funktioniert. Ein workaround ist hierfür aber nicht ohne weiteres drin.
Also ich hab mir jetzt den src gezogen, ins Eclipse importiert und die von Dir genannte Stelle mal angeschaut.
Ich stimme Dir mit Deiner Vermutung zu: das 1kB weise Schreiben in 13.2.0 statt 64 kB Schreiben so wie in 13.1.x sollte diejenigen Performance Einbrüche, die ich bei meinen Computern beim Download beobachte, zumindest zum Teil erklären.Eigentlich würde auch ich von einer Klasse, die sich BufferedOutputStream nennt, erwarten, daß sie so was abfedert. Nur scheint das bei Netzwerkzugriffen über SMB so nicht zu passieren schnief heul jammer
Im Prinzip fällt mir dazu ein simpler Workaround ein, der halt etwas RAM kostet. Memfile / pooling:
anstatt eines einzigen byte buffer[1024] nehme man zwei Puffer,
einen byte downloadBuffer[1024] und einen byte saveBuffer[1024 mal NPOOLS] -
im Schleifenrumpf schreibt man den Inhalt des downloadBuffer nicht in den fos.
Statt dessen kopiert man die Anzahl len der frisch per Download geholten Bytes ab der aktuellen Schlussposition saveBufferPos in den saveBuffer (zB mit System.arraycopy(downloadBuffer, 0, saveBuffer, saveBufferPos, len);).
Erst wenn NPOOLS voll sind (und nach der Schleife ggfs. den noch nicht gespeicherten Rest), schreibt man den saveBuffer in den fos, also (bis zu) 1024 mal NPOOLS Byte auf einmal.Ich hab bei mir mal NPOOLS auf 1024 gesetzt (also dem downloadBuffer 1MB RAM genehmigt) und mit meiner .class Datei per 7zip in MediathekView.jar die von Euch gelieferte ersetzt.
Die Downloadrate beträgt bei mir bei lokalem und Speicherort im Netzwerk (SMB-Freigabe) auf dem Kabelgebundenen Windows PC bei der Arte-Sendung ~21 MB/s – also knapp unter den 200 MBit/s von Kabelschland.
Sieht bei mir momentan bissl C artig aus – ich denke, da könnte man sicher eine feine kleine “Memfile” Klasse basteln um nicht die ganze hässliche Detail-Geschichte im DirectHttpDownload::downloadContent auszubreiten.
Falls Du an meiner Lösung interesse hast, einfach Bescheid geben.
Also vom Gefühl her könnt’s, ohne Gewehr, was werden. Hab’s aber noch nicht aufm WLAN Laptop getestet. Deine Forderung nach 1kB Downloads im MVBandwidthCountingInputStream ist in meinem workaround jedenfalls erfüllt, Dein Vorschlag großer memory-chunks für Filezugriffe ebenfalls. Es ist also eigentlich eh alles Deine Idee, ich würde halt einfach zwei Puffer statt einem machen.
-
Naja ich hab mit deinem Ansatz eigentlich mehrere Probleme:
Bei dir mag der Download Puffer von 1MByte das Schreiben beschleunigen. Auf anderen System wird das aber sicher zu Problemen führen.
Als Beispiel wäre auch wieder Windows zu nennen, wo bei MByte Puffergrößen die Schreibrate auf lokale Dateisysteme kollabiert. Hier ist 64KB der beste Wert.
Das nächste Problem ist das man aus Java nicht erkennen kann ob es sich um ein lokales Filesystem handelt oder um ein Network FS. Somit wird ein unterschiedliches Anwenden einer Logik schwierig.
Und das Hauptproblem: Es handelt sich (mal wieder) um ein windows-eigenes Problem, während sämtliche anderen gängigen Systeme keine Probleme haben. Da tu ich mich dann schon schwer (wieder mal) einen workaround für etwas zu basteln was eigentlich funktioniert.Was Du mal ausprobieren könntest. In meinem Code wird der BufferedOutputStream(fos) deklariert. Damit bekommt er wohl einen 8KB puffer zugewiesen. Änder den mal bitte auf BufferedOutputStream(fos, 64*1024) und mehr ab und schau bitte wie sich das verhält. Wenn das bei dir genau so einen guten Gewinn bringt könnte ich evtl die Puffergröße konfigurierbar machen in den Einstellungen.
-
Naja ich hab mit deinem Ansatz eigentlich mehrere Probleme:
Bei dir mag der Download Puffer von 1MByte das Schreiben beschleunigen. Auf anderen System wird das aber sicher zu Problemen führen.
Als Beispiel wäre auch wieder Windows zu nennen, wo bei MByte Puffergrößen die Schreibrate auf lokale Dateisysteme kollabiert. Hier ist 64KB der beste Wert.
Das nächste Problem ist das man aus Java nicht erkennen kann ob es sich um ein lokales Filesystem handelt oder um ein Network FS. Somit wird ein unterschiedliches Anwenden einer Logik schwierig.
Und das Hauptproblem: Es handelt sich (mal wieder) um ein windows-eigenes Problem, während sämtliche anderen gängigen Systeme keine Probleme haben. Da tu ich mich dann schon schwer (wieder mal) einen workaround für etwas zu basteln was eigentlich funktioniert.Was Du mal ausprobieren könntest. In meinem Code wird der BufferedOutputStream(fos) deklariert. Damit bekommt er wohl einen 8KB puffer zugewiesen. Änder den mal bitte auf BufferedOutputStream(fos, 64*1024) und mehr ab und schau bitte wie sich das verhält. Wenn das bei dir genau so einen guten Gewinn bringt könnte ich evtl die Puffergröße konfigurierbar machen in den Einstellungen.
@derreisende77 sagte in SMB:
Naja ich hab mit deinem Ansatz eigentlich mehrere Probleme:
Das ist schade. Ich versuche nur, Dir dabei zu helfen, Deine Annahme zu bestätigen und eine Lösungsvariante zu skizzieren. Unsere beiden Ansätze unterscheiden sich ja nur in einem Punkt: Java Bordmittel gegen selbst gebastelt. (und letzteres ist als proof of concept gedacht)
Bei dir mag der Download Puffer von 1MByte das Schreiben beschleunigen. Auf anderen System wird das aber sicher zu Problemen führen.
Nein und nein. Ich habe den Download Puffer bei 1 kByte gelassen! Und ich habe inzwischen Gegentests unter Ubuntu (VM, gehostet von Windows) und Knoppix (noch ein Debianid, rennt aber halt nativ)
Die Zahl von 1024 Pools war übrigens ein beliebig gewähltes Beispiel. 64 Pools st selbstverständlich auch ein Beispiel.Als Beispiel wäre auch wieder Windows zu nennen, wo bei MByte Puffergrößen die Schreibrate auf lokale Dateisysteme kollabiert. Hier ist 64KB der beste Wert.
Hm, ein guter Einwand. Wieder: 1 MByte Speicherpuffer waren ein beliebig gewähltes Beispiel, das von 1 kByte abweichen sollte. Ich hab zumindest zwei native Windows (beide Win 10 x64 18.03 Professional) getestet. Der Laptop PC kommt lokal auf SSD auf ~20 MB/s, extern auf Netzwerk auf ~9 MB/s (das sind 9 MB/s download + 9 MB/s speichern, beides über WLAN - und die FB schafft halt nur 20 MB/s zusammen. *, sh unten). Der Desktop mit GBit Kabel schafft auf HDD, auf SSD und auf Netzwerkfreigabe 22 MB/s MV Downloads.
Das ist kein umfassender Windows-Test. es fehlen alte Windows Versionen und 32-bit Systeme und andere Laufwerke (mein Desktop PC ist erst 7 Jahre). Aber es ist ein Anfang.Das nächste Problem ist das man aus Java nicht erkennen kann ob es sich um ein lokales Filesystem handelt oder um ein Network FS. Somit wird ein unterschiedliches Anwenden einer Logik schwierig.
Ich habe nicht vorgeschlagen eine plattform- oder dateisystemspezifische Lösung umzusetzen.
Und das Hauptproblem: Es handelt sich (mal wieder) um ein windows-eigenes Problem, während sämtliche anderen gängigen Systeme keine Probleme haben.
Nein. Es ist kein Windows Problem. Wenn er unter Knoppix läuft, weiß nicht mal mein PC, was Windows ist. Ich habe mir heute Nachmittag die Zeit genommen, um das zu testen. Bitte schaue nochmal mein Bilderbuch oben an. Die Werte der Ubuntu VM und von Knoppix haben beide bei lokalem Speichern noch bissl Luft nach oben. Die Werte der originalen 13.2.0 auf die Netzwerkfreigabe liegen bei 10% und weniger im Vergleich zu lokalem Speichern.
Da tu ich mich dann schon schwer (wieder mal) einen workaround für etwas zu basteln was eigentlich funktioniert.
Was Du mal ausprobieren könntest. In meinem Code wird der BufferedOutputStream(fos) deklariert. Damit bekommt er wohl einen 8KB puffer zugewiesen.
Den bos habe ich im Decompiler gesehen. Allerdings hattest Du mir immerhin, aber nur die .class Datei gegeben – und in diesem Fall ist die decompilierte Fassung nicht kompilierbar.
Aber ich weiß was Du meinst und ich konnte die Stelle gut in die git-Version mergen.Änder den mal bitte auf BufferedOutputStream(fos, 64*1024) und mehr ab und schau bitte wie sich das verhält. Wenn das bei dir genau so einen guten Gewinn bringt könnte ich evtl die Puffergröße konfigurierbar machen in den Einstellungen.
Ich habe die Änderung durchgeführt und getestet auf Laptop (lokal + Netzwerk), Desktop (lokal + Netzwerk) (Windows nativ, Ubuntu VM, KNoppix nativ)
Also mit dem von Dir vorgeschlagenen 64kB bos gibt es durchaus eine beachtliche Verbesserung gegenüber der originalen 13.2.
(mit selbstgestrickten 64 kB Memfiles hab ich (am Desktop unter Windows) übrigens ziemlich ähnliche Werte. - ich schätze, das liegt daran, dass bos mit Bordmitteln quasi genau das macht, was ich selbst gebastelt habe.)Aber hier nochmal zum Vergleich die Downloadgeschwindigkeiten beim Speichern auf Netzlaufwerk:
Ubuntu VM (64 kB bos: ~16 MB/S vs. 1MB MemFile: ~21 MB/s)
Knoppix nativ (64 kB bos: ~16 MB/s vs. 1 MB MemFile: ~21 MB/s)
Windows 10 (WLAN) (64 kB bos: ~2,5 MB/s vs 1 MB MemFile: ~9MB/s (sh. * oben))
Windows 10 (GBit Kabel) (64 kB bos: ~16 MB/s vs 1 MB MemFile: ~21MB/s)Wenn ich für mich ein Fazit ziehen darf:
Für mich sieht es (auf meinen Rechnern) so aus, als ob Deine erste Vermutung zutrifft, daß der Einbruch der Downloadgeschwindigkeit von der Puffergröße beim Speichern kommt.
Mein Eindruck ist, daß sich auf meinen Rechnern auf Linux und Windows gleichermaßen für lokales Speichern und Speichern im Netzwerk gleichermaßen das Erhöhen der Puffergröße siginifikant positiv auf die Downloadgeschwindigkeit auswirkt, teils mit dreistelligem Faktor.
(Zunächst nur) in den Tests auf meinen Rechnern unter 2x 2 Betriebssystemen (2x Windows, 2x Linux) zeigt sich 1 MB (Schreib)puffer als teilweise deutlich performanter und in keinem Test weniger performant als mit 64 kB bos.Eine Bibliotheksfunktion ist, bei gleicher Performance, einer selbstgebastelten Lösung vorzuziehen punkt.
Von daher finde ich persönlich den Ansatz mit dem bos für produktiven Einsatz zu bevorzugen, und die selbst gebastelte MemFile Geschichte ist was zum Spielen und Spaß haben für einen verregneten Nachmittag, mit dem Gefühl, daß eine Lösung für das von mir gemeldete Problem wohl mit einfachen Mitteln machbar ist. Und er hat, denke ich, exakt dasselbe Performance Potential: mit einem 1 MB bos habe ich eben noch zwei Film mit je 22+ MB/s vom Desktop PC lokal bzw. auf die Netzwerkfreigabe gespeichert.Als seit Jahren zufriedener MV-Nutzer würde ich mich freuen, wenn Du in der Klasse die bos Bibliothek zum Puffern verwenden würdest - und zwar am liebstn mit irgendeiner Möglichkeit, die Puffergröße zu regeln. Dann kann 1 kB in den Standard, und ich kann auf eigenes Risiko 1 MB gehen.
Viele Grüße
-
@derreisende77 sagte in SMB:
Naja ich hab mit deinem Ansatz eigentlich mehrere Probleme:
Das ist schade. Ich versuche nur, Dir dabei zu helfen, Deine Annahme zu bestätigen und eine Lösungsvariante zu skizzieren. Unsere beiden Ansätze unterscheiden sich ja nur in einem Punkt: Java Bordmittel gegen selbst gebastelt. (und letzteres ist als proof of concept gedacht)
Bei dir mag der Download Puffer von 1MByte das Schreiben beschleunigen. Auf anderen System wird das aber sicher zu Problemen führen.
Nein und nein. Ich habe den Download Puffer bei 1 kByte gelassen! Und ich habe inzwischen Gegentests unter Ubuntu (VM, gehostet von Windows) und Knoppix (noch ein Debianid, rennt aber halt nativ)
Die Zahl von 1024 Pools war übrigens ein beliebig gewähltes Beispiel. 64 Pools st selbstverständlich auch ein Beispiel.Als Beispiel wäre auch wieder Windows zu nennen, wo bei MByte Puffergrößen die Schreibrate auf lokale Dateisysteme kollabiert. Hier ist 64KB der beste Wert.
Hm, ein guter Einwand. Wieder: 1 MByte Speicherpuffer waren ein beliebig gewähltes Beispiel, das von 1 kByte abweichen sollte. Ich hab zumindest zwei native Windows (beide Win 10 x64 18.03 Professional) getestet. Der Laptop PC kommt lokal auf SSD auf ~20 MB/s, extern auf Netzwerk auf ~9 MB/s (das sind 9 MB/s download + 9 MB/s speichern, beides über WLAN - und die FB schafft halt nur 20 MB/s zusammen. *, sh unten). Der Desktop mit GBit Kabel schafft auf HDD, auf SSD und auf Netzwerkfreigabe 22 MB/s MV Downloads.
Das ist kein umfassender Windows-Test. es fehlen alte Windows Versionen und 32-bit Systeme und andere Laufwerke (mein Desktop PC ist erst 7 Jahre). Aber es ist ein Anfang.Das nächste Problem ist das man aus Java nicht erkennen kann ob es sich um ein lokales Filesystem handelt oder um ein Network FS. Somit wird ein unterschiedliches Anwenden einer Logik schwierig.
Ich habe nicht vorgeschlagen eine plattform- oder dateisystemspezifische Lösung umzusetzen.
Und das Hauptproblem: Es handelt sich (mal wieder) um ein windows-eigenes Problem, während sämtliche anderen gängigen Systeme keine Probleme haben.
Nein. Es ist kein Windows Problem. Wenn er unter Knoppix läuft, weiß nicht mal mein PC, was Windows ist. Ich habe mir heute Nachmittag die Zeit genommen, um das zu testen. Bitte schaue nochmal mein Bilderbuch oben an. Die Werte der Ubuntu VM und von Knoppix haben beide bei lokalem Speichern noch bissl Luft nach oben. Die Werte der originalen 13.2.0 auf die Netzwerkfreigabe liegen bei 10% und weniger im Vergleich zu lokalem Speichern.
Da tu ich mich dann schon schwer (wieder mal) einen workaround für etwas zu basteln was eigentlich funktioniert.
Was Du mal ausprobieren könntest. In meinem Code wird der BufferedOutputStream(fos) deklariert. Damit bekommt er wohl einen 8KB puffer zugewiesen.
Den bos habe ich im Decompiler gesehen. Allerdings hattest Du mir immerhin, aber nur die .class Datei gegeben – und in diesem Fall ist die decompilierte Fassung nicht kompilierbar.
Aber ich weiß was Du meinst und ich konnte die Stelle gut in die git-Version mergen.Änder den mal bitte auf BufferedOutputStream(fos, 64*1024) und mehr ab und schau bitte wie sich das verhält. Wenn das bei dir genau so einen guten Gewinn bringt könnte ich evtl die Puffergröße konfigurierbar machen in den Einstellungen.
Ich habe die Änderung durchgeführt und getestet auf Laptop (lokal + Netzwerk), Desktop (lokal + Netzwerk) (Windows nativ, Ubuntu VM, KNoppix nativ)
Also mit dem von Dir vorgeschlagenen 64kB bos gibt es durchaus eine beachtliche Verbesserung gegenüber der originalen 13.2.
(mit selbstgestrickten 64 kB Memfiles hab ich (am Desktop unter Windows) übrigens ziemlich ähnliche Werte. - ich schätze, das liegt daran, dass bos mit Bordmitteln quasi genau das macht, was ich selbst gebastelt habe.)Aber hier nochmal zum Vergleich die Downloadgeschwindigkeiten beim Speichern auf Netzlaufwerk:
Ubuntu VM (64 kB bos: ~16 MB/S vs. 1MB MemFile: ~21 MB/s)
Knoppix nativ (64 kB bos: ~16 MB/s vs. 1 MB MemFile: ~21 MB/s)
Windows 10 (WLAN) (64 kB bos: ~2,5 MB/s vs 1 MB MemFile: ~9MB/s (sh. * oben))
Windows 10 (GBit Kabel) (64 kB bos: ~16 MB/s vs 1 MB MemFile: ~21MB/s)Wenn ich für mich ein Fazit ziehen darf:
Für mich sieht es (auf meinen Rechnern) so aus, als ob Deine erste Vermutung zutrifft, daß der Einbruch der Downloadgeschwindigkeit von der Puffergröße beim Speichern kommt.
Mein Eindruck ist, daß sich auf meinen Rechnern auf Linux und Windows gleichermaßen für lokales Speichern und Speichern im Netzwerk gleichermaßen das Erhöhen der Puffergröße siginifikant positiv auf die Downloadgeschwindigkeit auswirkt, teils mit dreistelligem Faktor.
(Zunächst nur) in den Tests auf meinen Rechnern unter 2x 2 Betriebssystemen (2x Windows, 2x Linux) zeigt sich 1 MB (Schreib)puffer als teilweise deutlich performanter und in keinem Test weniger performant als mit 64 kB bos.Eine Bibliotheksfunktion ist, bei gleicher Performance, einer selbstgebastelten Lösung vorzuziehen punkt.
Von daher finde ich persönlich den Ansatz mit dem bos für produktiven Einsatz zu bevorzugen, und die selbst gebastelte MemFile Geschichte ist was zum Spielen und Spaß haben für einen verregneten Nachmittag, mit dem Gefühl, daß eine Lösung für das von mir gemeldete Problem wohl mit einfachen Mitteln machbar ist. Und er hat, denke ich, exakt dasselbe Performance Potential: mit einem 1 MB bos habe ich eben noch zwei Film mit je 22+ MB/s vom Desktop PC lokal bzw. auf die Netzwerkfreigabe gespeichert.Als seit Jahren zufriedener MV-Nutzer würde ich mich freuen, wenn Du in der Klasse die bos Bibliothek zum Puffern verwenden würdest - und zwar am liebstn mit irgendeiner Möglichkeit, die Puffergröße zu regeln. Dann kann 1 kB in den Standard, und ich kann auf eigenes Risiko 1 MB gehen.
Viele Grüße
hab mir grade den Quellcode von BufferedOutputStream angeschaut.
Das ist ja wirklich dasselbe in grün wie mein MemFile.
Jetzt hab ich wenigstens gelernt bzw. wiederholt, wie die Menschen in Java ohne Destruktor so leben. Kraß. Kann man spenden? ;-)Dann war das ganze für mich eine Wiederholung der Lektion, wozu try with resources gut ist und daß man, wenn der erste Versuch nicht klappt, nochmal javadoc lesen und alternative Konstruktoren mit sinnvolleren Parametern etc. suchen sollte. Danke! :-) -
und für das Projekt denke ich ein Erkenntnisgewinn, daß (meiner Meinung nach OS-übergreifend) ein angemessen großer Schreibpuffer den zumindest von mir in 13.2.0 erlittenen Performanceeinbruch beim Download wettmach(en könn)t. Und da hatten Du und ich denke ich ab Deinem Hinweis dieselbe Idee (nur anders, aber äquivalent hingeschrieben) und eigentlich nur eine Diskussion, was eine gute Puffergröße sein könnte.Die Frage sieht für mich so aus: gibt es “den” global besten Wert für die Puffergröße, oder gibt man einen vor und läßt dem Nutzer die Stellschraube. – Ich selbst kann mir ja künftig eine Patch-Version von MV bauen.
Danke für die Hilfe!
-
13.2.1 wird den Puffer manuell einstellen lassen in der config File. Habe ich fast fertig.
Und ja einen generisch besten wert gibt es für Windows: 64K. Den vertragen die alten Platten und das Windows VFS am besten. Der Rest kann über die config “optimieren”.
Und ja man kann Spenden. Der Link ist über die HP zu finden 😉